Spurred by Rafa’s post on evaluating statisticians working in genomics, there’s an interesting discussion going on at the Scientists for Reproducible Research group on statistics journals. Evan Johnson kicks it off:
…our statistics journals have little impact on how genomic data are analyzed. My group rarely looks to publish in statistics journals anymore because even IF we can get it published quickly, NO ONE will read it, so the only things we send there anymore are things that we don’t care if anyone ever uses.
Evan continues:
It’s crazy to me that all of our statistical journals are barely even noticed by bioinformaticians, computational biologists, and by people in genomics. Even worse, very few non-statisticians in genomics ever try to publish in our journals. Ultimately, this represents a major failure in the statistical discipline to be collectively influential on how genomic data are analyzed.
I may agree with the first point but I’m not sure I agree with second. Regarding the first, I think Karl put it best in that really the problem is that “the bulk of the people who might benefit from my method do not read the statistical literature”. For the second point, I think the issue is that the way science works is changing. Here’s my cartoon of how science worked in the “old days”, say, pre-computer era:
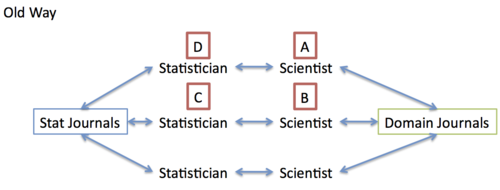
The idea here is that scientists worked with statisticians (they may have been one and the same) to publish stat papers and scientific papers. If Scientist A saw a paper in a domain journal written by Scientist B using a method developed by Statistician C, how could Scientist A apply that method? He had to talk to Statistician D, who would read that statistics literature and find Statistician C’s paper to learn about the method. The point is that there is no direct link from Scientist A to Statistician C except through statistics journals. Therefore, it was critical for Statistician C to publish in the stat journals to ensure that there would be an impact on scientists.
My cartoon of the “new way” of doing things is below.
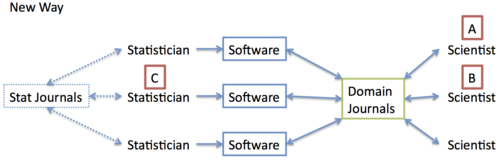
Now, if Scientist wants to use a method developed by Statistician C (and used by Scientist B), he simply finds the software developed by Statistician C and applies it to his data. Here, there is a direct connection between A and C through software. If Statistician C wants his method to have an impact on scientists, there are two options: publish in stat journals and hope that the method filters through other statisticians, or publish in domain journals with software so that other scientists may apply the method directly. It seems the latter approach is more popular in some areas.
Peter Diggle makes an important point about generalized linear models and the seminal book written by McCullagh and Nelder:
the book [by McCullagh and Nelder] would have been read by many fewer people if Nelder and colleague had not embedded the idea in software that (for the time) was innovative in being interactive rather than batch-oriented.
For better or for worse (and probably very often for worse), the software allowed many many people access to the methods.
The supposed attraction of publishing a statistical method in a statistics journal like JASA or JRSS-B is that the methods are published in a more abstract manner (usually using mathematical symbols) in the hopes that the methods will be applicable to a wide array of problems, not just the problem for which it was developed. Of course, the flip side of this argument is, as Karl says, again eloquently, “if you don’t get down to the specifics of a particular data set, then you haven’t really solved any problem”.
I think abstraction is important and we need to continue publishing those kinds of ideas. However, I think there is one key point that the statistics community has had difficulty grasping, which is that software represents an important form of abstraction, if not the most important form. Anyone who has written software knows that there are many approaches to implementing your method in software and various levels of abstraction one can use. The variety of problems to which the software can be applied depends on how general the interface to your software is. This is why I always encourage people to write R packages because it often forces them to think a bit more abstractly about who might be using the software.
Whither the statistics journals? It’s hard to say. Having them publish more software probably won’t help as the audience remains the same. I’m a bit stumped here but I look forward to continued discussion!