As explained in an earlier post, one of the homework assignments of my CS109 class was to predict the results of the midterm election. We created a competition in which 49 students entered. The most interesting challenge was to provide intervals for the republican - democrat difference in each of the 35 senate races. Anybody missing more than 2 was eliminated. The average size of the intervals was the tie breaker.
The main teaching objective here was to get students thinking about how to evaluate prediction strategies when chance is involved. To a naive observer, a biased strategy that favored democrats and correctly called, say, Virginia may look good in comparison to strategies that called it a toss-up. However, a look at the other 34 states would reveal the weakness of this biased strategy. I wanted students to think of procedures that can help distinguish lucky guesses from strategies that universally perform well.
One of the concepts we discussed in class was the systematic bias of polls which we modeled as a random effect. One can’t infer this bias from polls until after the election passes. By studying previous elections students were able to estimate the SE of this random effect and incorporate it into the calculation of intervals. The realization of this random effect was very large in these elections (about +4 for the democrats) which clearly showed the importance of modeling this source of variability. Strategies that restricted standard error measures to sample estimates from this year’s polls did very poorly. The 90% credible intervals provided by 538, which I believe does incorporate this, missed 8 of the 35 races (23%). This suggests that they underestimated the variance. Several of our students compared favorably to 538:
| name | avg bias | MSE | avg interval size |
missed |
|---|---|---|---|---|
| Manuel Andere | -3.9 | 6.9 | 24.1 | 3 |
| Richard Lopez | -5.0 | 7.4 | 26.9 | 3 |
| Daniel Sokol | -4.5 | 6.4 | 24.1 | 4 |
| Isabella Chiu | -5.3 | 9.6 | 26.9 | 6 |
| Denver Mosigisi Ogaro | -3.2 | 6.6 | 18.9 | 7 |
| Yu Jiang | -5.6 | 9.6 | 22.6 | 7 |
| David Dowey | -3.5 | 6.2 | 16.3 | 8 |
| Nate Silver | -4.2 | 6.6 | 16.4 | 8 |
| Filip Piasevoli | -3.5 | 7.4 | 22.1 | 8 |
| Yapeng Lu | -6.5 | 8.2 | 16.5 | 10 |
| David Jacob Lieb | -3.7 | 7.2 | 17.1 | 10 |
| Vincent Nguyen | -3.8 | 5.9 | 11.1 | 14 |
It is important to note that 538 would have probably increased their interval size had they actively participated in a competition requiring 95% of the intervals to cover. But all in all, students did very well. The majority correctly predicted the republican take over. The median mean square error across all 49 participantes was 8.2 which was not much worse that 538’s 6.6. Other example of strategies that I think helped some of these students perform well was the use of creative weighting schemes (based on previous elections) to average poll and the use of splines to estimate trends, which in this particular election were going in the republican’s favor.
Here are some plots showing results from two of our top performers:
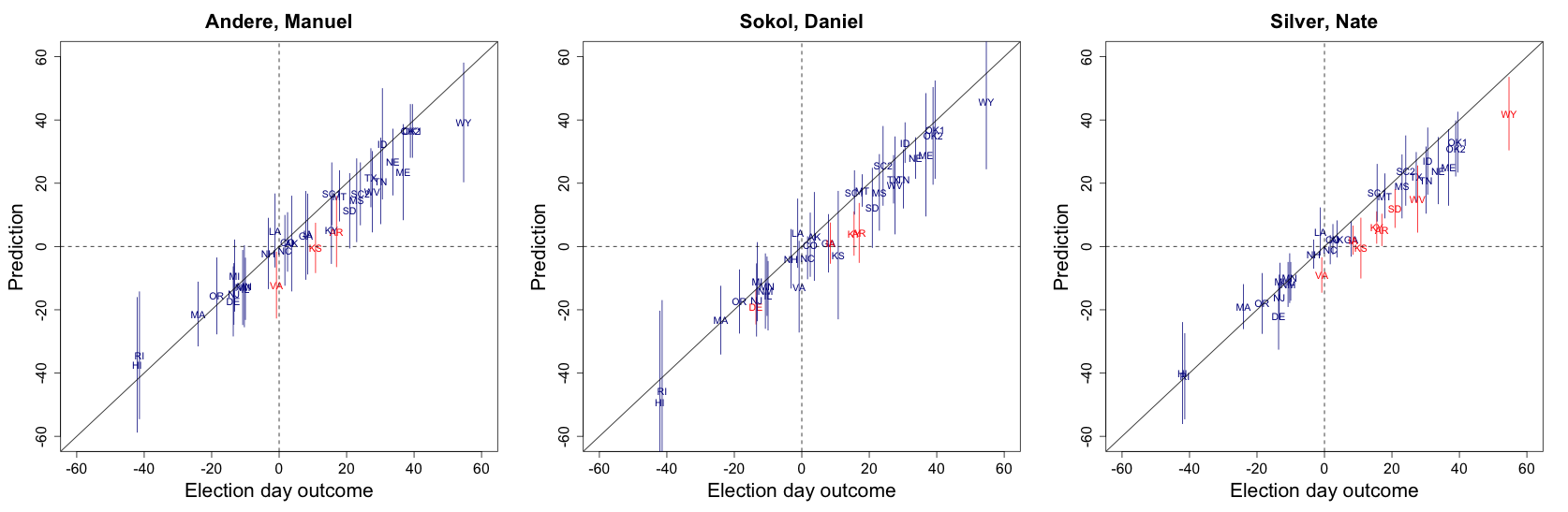

I hope this exercise helped students realize that data science can be both fun and useful. I can’t wait to do this again in 2016.